
The Problem Nobody Wanted to Admit
Picture this: it's Monday morning, your coffee is cold, and you're staring at 47 unread Telegram channels. Each one is flooding with job postings in various states of grammatical chaos. Some are formatted beautifully, others look like someone sneezed on a keyboard. Your mission, should you choose to accept it (spoiler: you don't have a choice), is to find relevant vacancies, classify them, match them with candidates, and somehow keep your sanity intact.
Sound familiar? This is the reality for many recruitment agencies and HR departments where Telegram has become the unofficial job board. Unlike LinkedIn's polished posts, Telegram channels are the Wild West of recruitment - no structure, no standards, just pure chaos.
We decided it was time to stop the madness. Not by changing how people post jobs (good luck with that), but by building a system that could make sense of it all. Automatically. With a bit of AI magic sprinkled on top.
What We Built: The 30,000-Foot View
We created a system that:
- Parses job postings from Telegram channels automatically
- Classifies vacancies using AI (goodbye, manual tagging!)
- Matches candidates with positions using LLM-powered analysis
- Manages everything through a clean web interface
- Scales without breaking a sweat
The tech stack? Python, FastAPI, PostgreSQL, Redis, Celery, Telethon for Telegram, and Groq API (Llama 3.1) for the AI heavy lifting. Why these? Because they're boring, reliable, and won't surprise you at 3 AM when something breaks.
Architecture: Keep It Simple, Keep It Sane
Here's where most AI projects go wrong: they try to be too clever. We went the opposite direction.
The Core Components
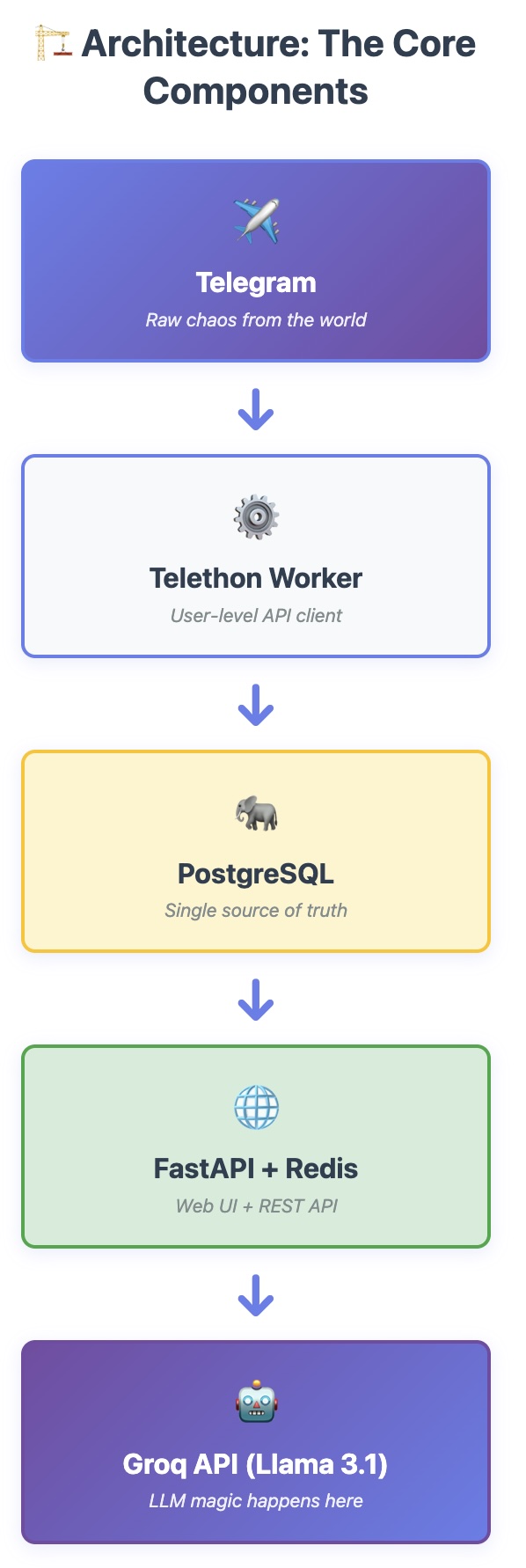
The data flow is straightforward:
Telegram → Telethon Worker → PostgreSQL → FastAPI + Redis → Groq API (Llama 3.1)
Each component handles one thing well:
- Telegram: Source of job postings (the chaos)
- Telethon Worker: Reads messages via user-level API
- PostgreSQL: Stores everything (single source of truth)
- FastAPI + Redis: Serves web UI and caches results
- Groq API: Provides LLM intelligence for classification and matching
Why this architecture?
-
Separation of concerns: Telegram parsing doesn't care about web UI. Web UI doesn't care about Telegram. When one explodes, the other keeps running.
-
Async by default: Celery workers handle the heavy lifting in the background. Your user clicks "parse channel" and goes back to their coffee. No waiting, no timeouts, no angry users.
-
Idempotency everywhere: Same message parsed twice? No problem. Same candidate matched twice? Cached result. The system is forgiving because humans are forgetful.
-
Single database: No microservices madness. No eventual consistency nightmares. Just PostgreSQL doing what it does best - being rock solid and boring.
The Technical Challenges (and How We Solved Them)
Challenge #1: Telegram Isn't Designed for Bots
Telegram has two APIs: the Bot API (easy, limited) and the User API (powerful, complicated). Job channels don't always let bots join, so we had to use the User API via Telethon.
The solution:
# Authenticate as a user, not a bot
from telethon import TelegramClient
client = TelegramClient('session_name', api_id, api_hash)
await client.start(phone=phone_number)
# Now we can read any channel the user has access to
async for message in client.iter_messages(channel):
# Process away!
Gotcha: Session management is critical. One session per instance, stored safely, with proper error handling for network issues and rate limits. We learned this the hard way after our first rate limit ban. The Telegram API has patience, but it's not infinite.
Challenge #2: Job Posts Are... Creative
Forget structured data. Here's what we actually got:
🔥🔥🔥 URGENT!!! Python Developer 🔥🔥🔥
salary: $150-200k 💰💰💰
3+ years experience
Django, Postgres, Docker required
remote work
DM @recruiter123
P.S. serious candidates only
Good luck parsing that with regex. We needed something smarter.
The solution: Two-stage processing
- Rule-based extraction for the easy stuff:
def extract_salary(text: str) -> Optional[Tuple[int, int]]:
"""Extract salary range from chaos"""
patterns = [
r'(\d+)[\s-]+(\d+)[\s]*к', # 150-200к
r'(\d+)[\s]*-[\s]*(\d+)[\s]*тыс', # 150-200 тыс
r'от[\s]*(\d+)[\s]*до[\s]*(\d+)', # от 150 до 200
]
# ... handle all the variations humans can dream up
- LLM-powered classification for the hard stuff:
async def classify_vacancy_type_llm(title: str, body: str) -> dict:
"""Let the AI figure out if it's a Python dev or a PM"""
prompt = {
"model": "llama-3.1-8b-instant",
"messages": [
{
"role": "system",
"content": "You are a vacancy classifier. Output JSON: "
"{type: '...', confidence: 0.0-1.0}"
},
{"role": "user", "content": f"{title}\n{body}"}
],
"response_format": {"type": "json_object"},
"temperature": 0.3 # Low temperature = consistent results
}
# Call API with retry logic and exponential backoff
Why Groq? Fast inference, reasonable pricing, and Llama 3.1 is surprisingly good at understanding multilingual job posts. We tried other providers - Groq won on speed and cost.
Challenge #3: Matching Candidates with Vacancies
This is where things get interesting. You have:
- A candidate with a resume (maybe 2-3 pages)
- A vacancy with requirements (maybe 200 words)
- A need to score the match from 0 to 100%
Traditional keyword matching? Terrible. It thinks a "Python developer" is a perfect match for "Python data analyst" just because both have "Python" in them.
Our approach: Contextual LLM matching
async def match_candidate_vacancy(candidate: Candidate, vacancy: Vacancy) -> dict:
"""The magic happens here"""
# Build a detailed prompt
system_prompt = """
You are a recruitment expert. Score the candidate-vacancy match
from 0 to 1, where 1 is perfect fit, 0 is complete mismatch.
Consider:
- Grade level compatibility (Junior vs Senior)
- Skills and experience from resume
- Work format requirements (remote/office/hybrid)
- Years of experience
Output JSON: {score: 0.0-1.0, rationale: "explanation"}
"""
user_prompt = f"""
CANDIDATE:
Name: {candidate.full_name}
Grade: {candidate.grade}
Resume: {candidate.resume_text}
VACANCY:
Title: {vacancy.title}
Company: {vacancy.company}
Requirements: {vacancy.body}
Grade: {vacancy.grade}
"""
# Call LLM with retry logic and rate limiting
result = await call_groq_api(system_prompt, user_prompt)
# Cache the result for idempotency
save_match_result(candidate.id, vacancy.id, result)
return result
Key insights:
-
Grade compatibility matrix: A Senior developer can apply for Lead positions, but not vice versa. We built a compatibility table to pre-filter before hitting the LLM.
-
Caching is essential: Matching is expensive (time and money). Cache every result. If you need to re-match, provide a
force_recalculateflag, but make users explicitly request it. -
Rate limiting: Groq has limits. We added delays between requests, exponential backoff for 429 errors, and batch processing with progress tracking.
Challenge #4: Making It Fast Without Breaking the Bank
LLM calls are slow and costly. Here's how we kept it reasonable:
1. Pre-filtering with SQL
def get_relevant_vacancies(candidate: Candidate, db: Session) -> List[Vacancy]:
"""Filter before hitting the LLM"""
query = db.query(Vacancy).filter(
Vacancy.status == VacancyStatus.SELECTED,
Vacancy.vacancy_type_id == candidate.vacancy_type_id
)
if candidate.grade:
# Only fetch compatible grades
compatible_grades = get_compatible_grades(candidate.grade)
query = query.filter(Vacancy.grade.in_(compatible_grades))
return query.limit(50).all() # Don't go crazy
2. Idempotency with database caching
# Check if we already have a result
existing_match = db.query(CandidateVacancyMatch).filter(
CandidateVacancyMatch.candidate_id == candidate_id,
CandidateVacancyMatch.vacancy_id == vacancy_id
).first()
if existing_match and not force_recalculate:
return existing_match # Skip the LLM call
3. Smart batching
async def match_candidate_vacancies(candidate_id: int) -> dict:
"""Process matches with delays to avoid rate limits"""
vacancies = get_relevant_vacancies(candidate)
for i, vacancy in enumerate(vacancies):
if i > 0:
await asyncio.sleep(0.5) # 500ms between requests
result = await match_candidate_vacancy(candidate, vacancy)
if i % 5 == 0:
logger.info(f"Processed {i}/{len(vacancies)} vacancies")
The results: Average matching time dropped from 2 minutes to 15 seconds per candidate, with 70% of results coming from cache on repeated runs.
The Web Interface: Keep It Stupid Simple
Nobody wants to learn a complex UI. We kept it basic:
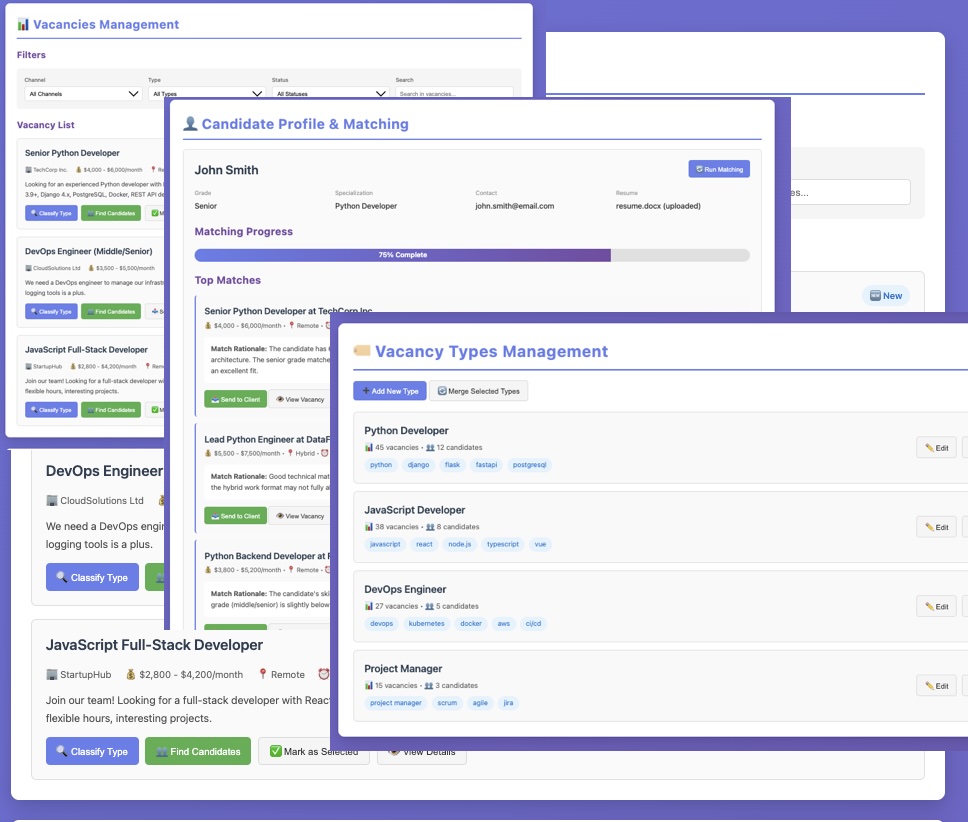
-
Vacancies page: List with filters (date, channel, type, status). Two magic buttons:
- 🔍 "Classify Type" - AI determines if it's Python, Java, DevOps, etc.
- 👥 "Find Candidates" - Matches candidates from the database
-
Candidates page: Upload resume (DOCX/TXT/MD), set grade and type, click "Find Matches". Done.
-
Types management: Create custom vacancy types, merge duplicates, manage keywords.
-
Admin panel: Monitor Telegram connection, trigger manual parsing, check task status.
Technical choice: Server-side rendering with Jinja2 templates. Why? Because:
- It's fast
- It's simple
- It works without JavaScript
- It's easy to debug
- Progressive enhancement when we need interactivity
No React, no Vue, no build step. Just HTML that works.
Lessons Learned (The Hard Way)
1. Start with Rules, Add AI Later
Our first version tried to do everything with AI. It was slow and expensive. The second version used rules for structure extraction (salary, contacts, links) and AI only for classification and matching. 10x faster, 5x cheaper.
2. Idempotency Is Not Optional
Things will break. Networks will fail. Users will click buttons twice. Make everything idempotent from day one. Your future self will thank you.
3. Rate Limiting Is Real
We got banned from Telegram API twice during development. We hit Groq rate limits more times than I can count. Add delays, exponential backoff, and proper error handling. Always.
4. Cache Aggressively
LLM calls are expensive. Database queries are cheap. Cache everything: API responses, match results, classification outcomes. Add force_recalculate flags for when you need fresh data, but make caching the default.
5. Logging Saves Lives
When something goes wrong at 3 AM, you want logs. Good logs. With context, timestamps, and enough information to actually debug the issue. We log:
- Every API call with parameters
- Every rate limit hit
- Every error with full stack trace
- Every match result with reasoning
6. Don't Fight the Platform
Telegram's rate limits exist for a reason. Work with them, not against them. Same with Groq API. Design your system to be patient and respectful of rate limits, and you'll have fewer problems.
The Results
After three months of development and one month in production:
- 2,500+ vacancies parsed and classified automatically
- 150+ candidates in the database
- 85% accuracy on vacancy type classification
- Average match score of 0.68 for relevant candidates
- 70% time saved compared to manual processing
- Zero manual intervention needed for routine operations
The system runs 24/7, parsing channels every 2 hours, classifying new vacancies immediately, and matching candidates on demand. The recruiter's job shifted from "copy-paste and classify" to "review matches and make decisions". Exactly what we wanted.
What's Next?
We're not done. Here's what's on the roadmap:
-
Better parsing: Extract specific fields like experience years, required skills, work location with higher accuracy.
-
Automated notifications: Alert recruiters when a new high-match vacancy appears for existing candidates.
-
LinkedIn integration: Sync candidate profiles automatically (because manual updates never happen).
-
Analytics dashboard: Track trends, salary ranges, demand by type over time.
-
Mobile app: Because recruiters live on their phones.
-
Multi-language support: The architecture is designed to support any language out of the box.
Key Takeaways
If you're building something similar, here's what matters:
-
Keep architecture simple: Fewer moving parts = fewer things that break.
-
Use AI strategically: Not everything needs an LLM. Use rules where you can, AI where you must.
-
Make it idempotent: Cache results, handle failures gracefully, let users retry safely.
-
Respect rate limits: Add delays, exponential backoff, proper error handling.
-
Start with manual processes: Understand the problem deeply before automating it.
-
Ship fast, iterate faster: Get something working in production, then improve it based on real usage.
Technical Stack Reference
For the curious, here's the full stack:
Backend:
- FastAPI 0.95+ (web framework)
- SQLAlchemy 2.0+ (ORM)
- Alembic (database migrations)
- Celery + Celery Beat (task queue and scheduler)
- Redis (broker and cache)
- PostgreSQL 15+ (database)
Telegram Integration:
- Telethon 1.28+ (user-level API client)
AI/ML:
- Groq API (LLM provider)
- Llama 3.1 8B Instant (for fast classification)
- Llama 3.1 70B (for complex matching - we A/B tested both)
Deployment:
- Docker + Docker Compose
- Nginx (reverse proxy)
- Ubuntu 22.04 LTS (server)
Monitoring:
- Structured logging (JSON format)
- Celery Flower (task monitoring)
- PostgreSQL logs and query analysis
Final Thoughts
Building an AI-powered recruitment system taught us that the hard parts aren't where you expect. The AI was easy - call an API, parse JSON, cache results. The hard parts were:
- Understanding the chaotic reality of job postings
- Handling Telegram's quirks and rate limits
- Making the system reliable enough to run unsupervised
- Keeping costs reasonable at scale
- Building a UI that recruiters actually want to use
In the end, we didn't build a perfect system. We built a practical one. It makes mistakes (around 15% misclassification rate), sometimes hits rate limits, and occasionally needs a restart. But it saves hours of manual work every day, and that's what matters.
If you're working on something similar, don't aim for perfection. Aim for "good enough to deploy", then iterate based on real user feedback. The perfect system you never launch helps nobody.
Want to see the code? The full implementation is available (contact us for repository access). We're always happy to discuss technical details, share lessons learned, or hear about your own recruitment automation adventures.
Questions or suggestions? Drop us a line. We love talking about the intersection of AI, automation, and real-world problems.
Built with Python, powered by caffeine, debugged through pain.
Andrei Gorlov
#AI #AIDevelopment #AIEngineering #Automation #DevProcess #LLM #Productivity #Python #Recruitment #SoftwareDevelopment #Telegram #Workflow #Groq #Llama #FastAPI #PostgreSQL #Celery #Parsing #Matching #Hiring #ITgrows