
Проблем који нико није хтео да призна
Замислите ово: понедељак ујутро, ваша кафа је хладна, а ви зурите у 47 непрочитаних Telegram канала. Сваки од њих се препуњава огласима за посао у различитим стањима граматичког хаоса. Неки су форматирани прелепо, други изгледају као да је неко кијао на тастатуру. Ваша мисија, ако одлучите да је прихватите (спојлер: немате избора), је да пронађете релевантне вакансије, класификујете их, упарите са кандидатима, и некако очувате своје здравље.
Звучи познато? Ово је реалност за многе регрутационе агенције и HR одељења где је Telegram постао незваничан портал за послове. За разлику од полираних постова на LinkedIn-у, Telegram канали су Дивљи Запад регрутације - нема структуре, нема стандарда, само чист хаос.
Одлучили смо да зауставимо лудило. Не тако што ћемо променити начин на који људи објављују послове (срећно са тим), већ изградњом система који може све то да схвати. Аутоматски. Са мало AI магије посуте одозго.
Шта смо изградили: Поглед са 30.000 стопа
Створили смо систем који:
- Парсује огласе за посао из Telegram канала аутоматски
- Класификује вакансије користећи AI (збогом, ручно обележавање!)
- Упарује кандидате са позицијама користећи LLM анализу
- Управља свиме кроз чист веб интерфејс
- Скалира без знојења
Технолошки стек? Python, FastAPI, PostgreSQL, Redis, Celery, Telethon за Telegram, и Groq API (Llama 3.1) за тешко AI подизање. Зашто ови? Зато што су досадни, поуздани, и неће вас изненадити у 3 ујутро када нешто крене наопако.
Архитектура: Одржите је једноставном, одржите је нормалном
Ево где већина AI пројеката крене наопако: покушавају да буду превише паметни. Ми смо отишли у супротном правцу.
Основне компоненте
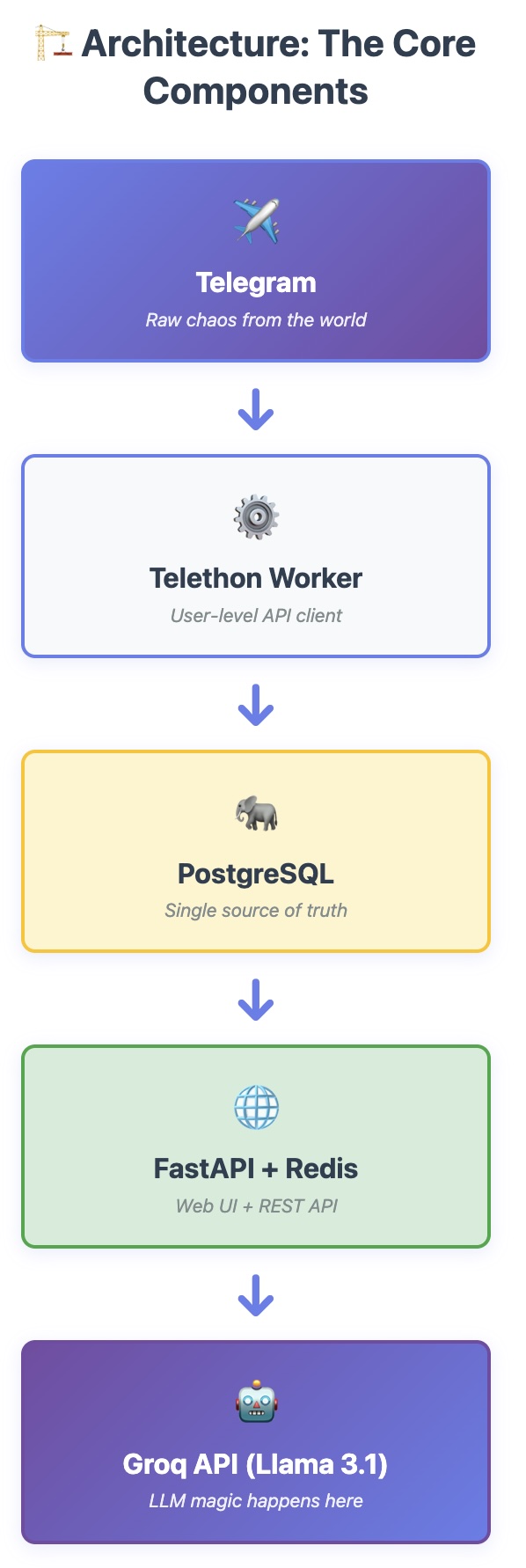
Ток података је директан:
Telegram → Telethon Worker → PostgreSQL → FastAPI + Redis → Groq API (Llama 3.1)
Свака компонента се бави једном ствари добро:
- Telegram: Извор огласа за посао (хаос)
- Telethon Worker: Чита поруке преко user-level API-ја
- PostgreSQL: Складишти све (јединствени извор истине)
- FastAPI + Redis: Служи веб UI и кешира резултате
- Groq API: Пружа LLM интелигенцију за класификацију и упаривање
Зашто ова архитектура?
-
Раздвајање бриге: Telegram парсовање не мари за веб UI. Веб UI не мари за Telegram. Када један експлодира, други наставља да ради.
-
Async по подразумеваним: Celery радници управљају тешким радом у позадини. Ваш корисник кликне "парсуј канал" и враћа се својој кафи. Нема чекања, нема timeout-а, нема бесних корисника.
-
Идемпотентност свуда: Иста порука парсована два пута? Нема проблема. Исти кандидат упарен два пута? Кеширани резултат. Систем је опростив јер су људи заборавни.
-
Једна база података: Нема лудила микросервиса. Нема ноћних мора евентуалне конзистентности. Само PostgreSQL ради оно што најбоље уме - буде чврст као стена и досадан.
Технички изазови (и како смо их решили)
Изазов #1: Telegram није дизајниран за ботове
Telegram има два API-ја: Bot API (лак, ограничен) и User API (моћан, компликован). Канали за послове не дозвољавају увек ботовима да се придруже, па смо морали да користимо User API преко Telethon-а.
Решење:
# Аутентификујте се као корисник, не као бот
from telethon import TelegramClient
client = TelegramClient('session_name', api_id, api_hash)
await client.start(phone=phone_number)
# Сада можемо да читамо било који канал коме корисник има приступ
async for message in client.iter_messages(channel):
# Обрађујте!
Замка: Управљање сесијом је критично. Једна сесија по инстанци, безбедно складиштена, са правилним руковањем грешкама за мрежне проблеме и rate limits. Научили смо то на тежак начин након нашег првог rate limit бана. Telegram API има стрпљења, али оно није бесконачно.
Изазов #2: Огласи за посао су... креативни
Заборавите структуриране податке. Ево шта смо заправо добили:
🔥🔥🔥 ХИТНО!!! Python програмер 🔥🔥🔥
плата: $150-200k 💰💰💰
3+ године искуства
Django, Postgres, Docker потребно
рад на даљину
пишите @recruiter123
P.S. само озбиљни кандидати
Срећно са парсовањем тога regex-ом. Требало нам је нешто паметније.
Решење: Двофазна обрада
- Екстракција заснована на правилима за лакествари:
def extract_salary(text: str) -> Optional[Tuple[int, int]]:
"""Извуците распон плате из хаоса"""
patterns = [
r'(\d+)[\s-]+(\d+)[\s]*к', # 150-200к
r'(\d+)[\s]*-[\s]*(\d+)[\s]*тыс', # 150-200 тыс
r'от[\s]*(\d+)[\s]*до[\s]*(\d+)', # от 150 до 200
]
# ... руковати свим варијацијама које људи могу да смисле
- LLM-покренута класификација за тешке ствари:
async def classify_vacancy_type_llm(title: str, body: str) -> dict:
"""Нека AI схвати да ли је Python dev или PM"""
prompt = {
"model": "llama-3.1-8b-instant",
"messages": [
{
"role": "system",
"content": "You are a vacancy classifier. Output JSON: "
"{type: '...', confidence: 0.0-1.0}"
},
{"role": "user", "content": f"{title}\n{body}"}
],
"response_format": {"type": "json_object"},
"temperature": 0.3 # Ниска температура = конзистентни резултати
}
# Позовите API са retry логиком и експоненцијалним backoff-ом
Зашто Groq? Брза инференција, разумне цене, и Llama 3.1 је изненађујуће добра у разумевању вишејезичких огласа за послове. Испробали смо друге провајдере - Groq је победио на брзини и цени.
Изазов #3: Упаривање кандидата са вакансијама
Овде ствари постају интересантне. Имате:
- Кандидата са резимеом (можда 2-3 странице)
- Вакансију са захтевима (можда 200 речи)
- Потребу да оцените подударање од 0 до 100%
Традиционално упаривање кључних речи? Ужасно. Мисли да је "Python developer" савршено подударање за "Python data analyst" само зато што оба имају "Python" у себи.
Наш приступ: Контекстуално LLM упаривање
async def match_candidate_vacancy(candidate: Candidate, vacancy: Vacancy) -> dict:
"""Магија се дешава овде"""
# Изградите детаљан промпт
system_prompt = """
Ви сте експерт за регрутацију. Оцените подударање кандидат-вакансија
од 0 до 1, где је 1 савршено подударање, 0 је потпуно неподударање.
Размотрите:
- Компатибилност нивоа (Junior vs Senior)
- Вештине и искуство из резимеа
- Захтеве формата рада (удаљено/канцеларија/хибридно)
- Године искуства
Output JSON: {score: 0.0-1.0, rationale: "објашњење"}
"""
user_prompt = f"""
КАНДИДАТ:
Име: {candidate.full_name}
Ниво: {candidate.grade}
Резиме: {candidate.resume_text}
ВАКАНСИЈА:
Наслов: {vacancy.title}
Компанија: {vacancy.company}
Захтеви: {vacancy.body}
Ниво: {vacancy.grade}
"""
# Позовите LLM са retry логиком и rate limiting-ом
result = await call_groq_api(system_prompt, user_prompt)
# Кеширајте резултат за идемпотентност
save_match_result(candidate.id, vacancy.id, result)
return result
Кључни увиди:
-
Матрица компатибилности нивоа: Senior developer може да се пријави за Lead позиције, али не обрнуто. Изградили смо табелу компатибилности да пре-филтрирамо пре него што погодимо LLM.
-
Кеширање је есенцијално: Упаривање је скупо (време и новац). Кеширајте сваки резултат. Ако треба да поново упарујете, обезбедите
force_recalculateзаставицу, али натерајте кориснике да то експлицитно захтевају. -
Rate limiting: Groq има ограничења. Додали смо кашњења између захтева, експоненцијални backoff за 429 грешке, и batch обраду са праћењем напретка.
Изазов #4: Учините га брзим без пуцања буџета
LLM позиви су спори и скупи. Ево како смо то одржали разумним:
1. Пре-филтрирање са SQL
def get_relevant_vacancies(candidate: Candidate, db: Session) -> List[Vacancy]:
"""Филтрирајте пре него што погодите LLM"""
query = db.query(Vacancy).filter(
Vacancy.status == VacancyStatus.SELECTED,
Vacancy.vacancy_type_id == candidate.vacancy_type_id
)
if candidate.grade:
# Само преузмите компатибилне нивое
compatible_grades = get_compatible_grades(candidate.grade)
query = query.filter(Vacancy.grade.in_(compatible_grades))
return query.limit(50).all() # Не полудите
2. Идемпотентност са кеширањем базе података
# Проверите да ли већ имамо резултат
existing_match = db.query(CandidateVacancyMatch).filter(
CandidateVacancyMatch.candidate_id == candidate_id,
CandidateVacancyMatch.vacancy_id == vacancy_id
).first()
if existing_match and not force_recalculate:
return existing_match # Прескочите LLM позив
3. Паметно груписање
async def match_candidate_vacancies(candidate_id: int) -> dict:
"""Обрадите подударања са кашњењима да избегнете rate limits"""
vacancies = get_relevant_vacancies(candidate)
for i, vacancy in enumerate(vacancies):
if i > 0:
await asyncio.sleep(0.5) # 500ms између захтева
result = await match_candidate_vacancy(candidate, vacancy)
if i % 5 == 0:
logger.info(f"Обрађено {i}/{len(vacancies)} вакансија")
Резултати: Просечно време упаривања пало са 2 минута на 15 секунди по кандидату, са 70% резултата који долазе из кеша на поновљеним покретањима.
Веб интерфејс: Одржите га глупо једноставним
Нико не жели да учи сложен UI. Одржали смо га основним:
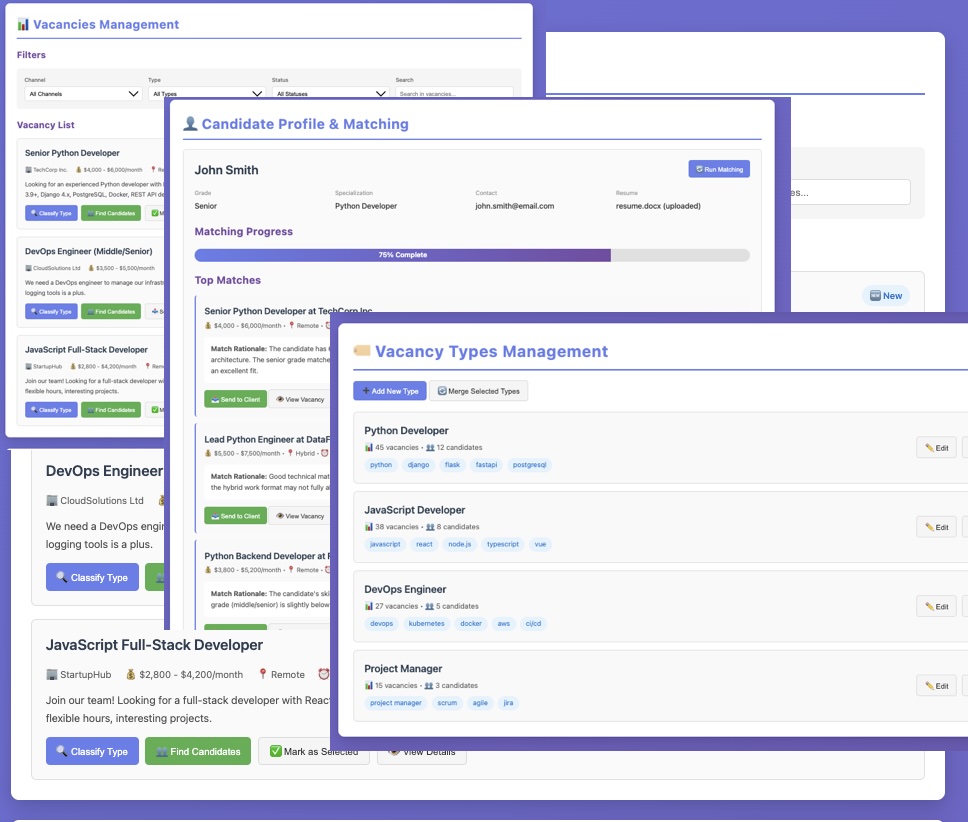
-
Страница вакансија: Листа са филтерима (датум, канал, тип, статус). Два магична дугмета:
- 🔍 "Класификуј тип" - AI одређује да ли је Python, Java, DevOps, итд.
- 👥 "Пронађи кандидате" - Упарује кандидате из базе података
-
Страница кандидата: Отпремите резиме (DOCX/TXT/MD), поставите ниво и тип, кликните "Пронађи подударања". Готово.
-
Управљање типовима: Креирајте прилагођене типове вакансија, спојите дупликате, управљајте кључним речима.
-
Админ панел: Надгледајте Telegram везу, покрените ручно парсовање, проверите статус задатка.
Технички избор: Server-side rendering са Jinja2 шаблонима. Зашто? Зато што:
- Брзо је
- Једноставно је
- Ради без JavaScript-а
- Лако је за дебагирање
- Прогресивно побољшање када нам треба интерактивност
Нема React-а, нема Vue-а, нема build корака. Само HTML који ради.
Лекције научене (на тежак начин)
1. Почните са правилима, додајте AI касније
Наша прва верзија је покушала да уради све са AI-јем. Било је споро и скупо. Друга верзија је користила правила за екстракцију структуре (плата, контакти, линкови) и AI само за класификацију и упаривање. 10x брже, 5x јефтиније.
2. Идемпотентност није опциона
Ствари ће се покварити. Мреже ће пасти. Корисници ће кликнути дугмад два пута. Учините све идемпотентним од првог дана. Ваше будуће ја ће вам захвалити.
3. Rate Limiting је реалан
Бановани смо из Telegram API-ја два пута током развоја. Погодили смо Groq rate limits више пута него што могу да избројим. Додајте кашњења, експоненцијални backoff, и правилно руковање грешкама. Увек.
4. Кеширајте агресивно
LLM позиви су скупи. Упити базе података су јефтини. Кеширајте све: API одговоре, резултате упаривања, исходе класификације. Додајте force_recalculate заставице за када су вам потребни свежи подаци, али учините кеширање подразумеваним.
5. Логовање спашава животе
Када нешто крене наопако у 3 ујутро, желите логове. Добре логове. Са контекстом, временским печатима, и довољно информација да заправо дебагујете проблем. Логујемо:
- Сваки API позив са параметрима
- Свако rate limit погађање
- Сваку грешку са пуним stack trace-ом
- Сваки резултат упаривања са образложењем
6. Не борите се против платформе
Telegram-ова rate ограничења постоје из разлога. Радите са њима, не против њих. Исто са Groq API-јем. Дизајнирајте ваш систем да буде стрпљив и поштован према rate ограничењима, и имаћете мање проблема.
Резултати
Након три месеца развоја и једног месеца у продукцији:
- 2,500+ вакансија парсовано и класификовано аутоматски
- 150+ кандидата у бази података
- 85% тачности на класификацији типа вакансије
- Просечан скор подударања од 0.68 за релевантне кандидате
- 70% уштеђеног времена у поређењу са ручном обрадом
- Нула ручних интервенција потребно за рутинске операције
Систем ради 24/7, парсује канале сваких 2 сата, класификује нове вакансије одмах, и упарује кандидате на захтев. Посао регрутера се померио са "копирај-налепи и класификуј" на "прегледај подударања и доноси одлуке". Тачно оно што смо желели.
Шта је следеће?
Нисмо завршили. Ево шта је на путокажу:
-
Боље парсовање: Извуците специфична поља попут година искуства, потребних вештина, локације рада са већом тачношћу.
-
Аутоматизована обавештења: Упозорите регрутере када се појави нова високо-подударајућа вакансија за постојеће кандидате.
-
LinkedIn интеграција: Синхронизујте профиле кандидата аутоматски (јер ручна ажурирања никада се не дешавају).
-
Аналитички дешборд: Пратите трендове, распоне плата, потражњу по типу током времена.
-
Мобилна апликација: Јер регрутери живе на својим телефонима.
-
Подршка за више језика: Архитектура је дизајнирана да подржава било који језик од почетка.
Кључни закључци
Ако градите нешто слично, ево шта је важно:
-
Одржите архитектуру једноставном: Мање покретних делова = мање ствари које се квари.
-
Користите AI стратешки: Не треба све LLM. Користите правила где можете, AI где морате.
-
Учините га идемпотентним: Кеширајте резултате, руковајте неуспесима грациозно, дозволите корисницима да безбедно покушају поново.
-
Поштујте rate limits: Додајте кашњења, експоненцијални backoff, правилно руковање грешкама.
-
Почните са ручним процесима: Разумите проблем дубоко пре него што га аутоматизујете.
-
Испоручите брзо, итерирајте брже: Добијте нешто што ради у продукцији, затим побољшајте на основу праве употребе.
Референца техничког стека
За радознале, ево пуног стека:
Backend:
- FastAPI 0.95+ (web framework)
- SQLAlchemy 2.0+ (ORM)
- Alembic (database migrations)
- Celery + Celery Beat (task queue and scheduler)
- Redis (broker and cache)
- PostgreSQL 15+ (database)
Telegram интеграција:
- Telethon 1.28+ (user-level API client)
AI/ML:
- Groq API (LLM provider)
- Llama 3.1 8B Instant (за брзу класификацију)
- Llama 3.1 70B (за сложено упаривање - A/B тестирали смо оба)
Deployment:
- Docker + Docker Compose
- Nginx (reverse proxy)
- Ubuntu 22.04 LTS (server)
Надгледање:
- Структурирано логовање (JSON формат)
- Celery Flower (праћење задатака)
- PostgreSQL логови и query анализа
Завршне мисли
Изградња AI-покренутог система за регрутацију нас је научила да тешки делови нису тамо где очекујете. AI је био лак - позовите API, парсујте JSON, кеширајте резултате. Тешки делови су били:
- Разумевање хаотичне реалности огласа за послове
- Руковање Telegram-овим чудностима и rate limits
- Чињење система довољно поузданим да ради без надзора
- Одржавање разумних трошкова у скали
- Изградња UI-ја који регрутери заправо желе да користе
На крају, нисмо изградили савршен систем. Изградили смо практичан. Прави грешке (око 15% стопа погрешне класификације), понекад погађа rate limits, и повремено треба рестарт. Али штеди сате ручног рада сваког дана, и то је оно што је важно.
Ако радите на нечему сличном, не циљајте на савршенство. Циљајте на "довољно добро за deploy", затим итерирајте на основу праве повратне информације корисника. Савршен систем који никада не лансирате никоме не помаже.
Желите да видите код? Пуна имплементација је доступна (контактирајте нас за приступ репозиторијуму). Увек смо срећни да разговарамо о техничким детаљима, делимо научене лекције, или чујемо о вашим сопственим авантурама са аутоматизацијом регрутације.
Питања или сугестије? Јавите нам се. Волимо да причамо о раскршћу AI-ја, аутоматизације и проблема из стварног света.
Изграђено са Python-ом, покренуто кофеином, дебаговано кроз бол.
Андреј Горлов